
C# Records have been out for a while now and I purposely avoided jumping on the band wagon as all the other bloggers out there in were proclaiming how amazing they are. In my opinion, C# Records have been out just long enough for developers to start using them and unfortunately also misusing them. I am encountering a number of situations where Records are being used and it makes no sense why and none of the functionality they provide is being used.
Over the past few months, I've read a number of blog posts and articles about C# Records and listened to many opinions on why they are are the greatest thing since sliced bread. However, I've already started exploring code bases where Records have been implemented for actually no discernible reason.
I wanted to dive deeper into record types in order to highlight the situations where they make sense to use and why they shouldn't just be used everywhere. I am getting the sense that developers are just making use of C# Records because they're there and they're supposedly cool or even thought to be the cure for all code cancers!
I just want to preface this article, I am not against C# Records or even the concepts of immutability in code. They are great and I use them often, I think for the most part its just understanding of when, why and where to use them is far more important than just using them.
All too often you'll find in code bases, that things have been implemented to overcome situations, that if you just take a step back and think about the problem a little more you'll find a far more elegant solution. This post has been heavily inspired by just that type of situation. Where developers have opted to make use of particular new language features and concepts to solve a problem, that in reality did not need to solved with the use of Records and immutability. It is the intention of this post, to understand the features and highlight situations and problems that these features and concepts are of real benefit, and not just use these concepts everywhere.
I have endeavoured to try and simplify particular situations as much as I can, in order to try and focus on particular scenarios, I appreciate that these may be somewhat over simplified but I hope they relay the context.
What are C# Records
The best explanatory phrase I've heard used to explain what C# Records are and pretty much nails their ideal use case in one is:
Record types are immutable reference types that provide value semantics for equality.
The key points that need to be gleaned from this that the properties of an instance of a reference type cannot change after its initialisation and hence make them great fit in situations when you're going to need to evaluate objects to see if they are equal to each other.
This is the stand out reason why you would want to use C# Records they are ideal in situations where you are going to need to compare objects and maybe you want to ensure the property values of an object cannot be changed during the execution of other processes.
Value types and Reference types are the two main categories of C# types.
Value Types
A variable of a value type contains an instance of the type.
A value type can be one of the two following kinds:
- a structure type, which encapsulates data and related functionality
- an enumeration type, which is defined by a set of named constants and represents a choice or a combination of choices
Reference Types
Variables of reference types store references to their data (objects)
The following keywords are used to declare reference types:
classinterfacedelegaterecord
Lets take a deeper look into the code behind a relatively simple C# Record. We'll define a simple C# Person Record, which will have two properties for FirstName and LastName.
public record Person(string FirstName, string LastName);
A record is still a class, but the record keyword imbues it with several additional value-like behaviors. Generally speaking, records are defined by their contents, not their identity. In this regard, records are much closer to structs, but records are still reference types.
If we decompile this code, using one of my favourite tools Sharplab.io, to inspect the code that is actually generated, we'll see that a lot of code will be generated for effectively is a really simple object. We'll discover from this that a C# Record is nothing more than some Syntactical sugar for a class that the implements the IEquatable interface.
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Reflection;
using System.Runtime.CompilerServices;
using System.Security;
using System.Security.Permissions;
using System.Text;
using Microsoft.CodeAnalysis;
[assembly: CompilationRelaxations(8)]
[assembly: RuntimeCompatibility(WrapNonExceptionThrows = true)]
[assembly: Debuggable(DebuggableAttribute.DebuggingModes.Default | DebuggableAttribute.DebuggingModes.DisableOptimizations | DebuggableAttribute.DebuggingModes.IgnoreSymbolStoreSequencePoints | DebuggableAttribute.DebuggingModes.EnableEditAndContinue)]
[assembly: SecurityPermission(SecurityAction.RequestMinimum, SkipVerification = true)]
[assembly: AssemblyVersion("0.0.0.0")]
[module: UnverifiableCode]
namespace Microsoft.CodeAnalysis
{
[CompilerGenerated]
[Embedded]
internal sealed class EmbeddedAttribute : Attribute
{
}
}
namespace System.Runtime.CompilerServices
{
[CompilerGenerated]
[Microsoft.CodeAnalysis.Embedded]
[AttributeUsage(AttributeTargets.Class | AttributeTargets.Property | AttributeTargets.Field | AttributeTargets.Event | AttributeTargets.Parameter | AttributeTargets.ReturnValue | AttributeTargets.GenericParameter, AllowMultiple = false, Inherited = false)]
internal sealed class NullableAttribute : Attribute
{
public readonly byte[] NullableFlags;
public NullableAttribute(byte P_0)
{
byte[] array = new byte[1];
array[0] = P_0;
NullableFlags = array;
}
public NullableAttribute(byte[] P_0)
{
NullableFlags = P_0;
}
}
[CompilerGenerated]
[Microsoft.CodeAnalysis.Embedded]
[AttributeUsage(AttributeTargets.Class | AttributeTargets.Struct | AttributeTargets.Method | AttributeTargets.Interface | AttributeTargets.Delegate, AllowMultiple = false, Inherited = false)]
internal sealed class NullableContextAttribute : Attribute
{
public readonly byte Flag;
public NullableContextAttribute(byte P_0)
{
Flag = P_0;
}
}
}
public class Person : IEquatable<Person>
{
[CompilerGenerated]
[DebuggerBrowsable(DebuggerBrowsableState.Never)]
private readonly string <FirstName>k__BackingField;
[CompilerGenerated]
[DebuggerBrowsable(DebuggerBrowsableState.Never)]
private readonly string <LastName>k__BackingField;
[System.Runtime.CompilerServices.Nullable(1)]
protected virtual Type EqualityContract
{
[System.Runtime.CompilerServices.NullableContext(1)]
[CompilerGenerated]
get
{
return typeof(Person);
}
}
public string FirstName
{
[CompilerGenerated]
get
{
return <FirstName>k__BackingField;
}
[CompilerGenerated]
init
{
<FirstName>k__BackingField = value;
}
}
public string LastName
{
[CompilerGenerated]
get
{
return <LastName>k__BackingField;
}
[CompilerGenerated]
init
{
<LastName>k__BackingField = value;
}
}
public Person(string FirstName, string LastName)
{
<FirstName>k__BackingField = FirstName;
<LastName>k__BackingField = LastName;
base..ctor();
}
public override string ToString()
{
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.Append("Person");
stringBuilder.Append(" { ");
if (PrintMembers(stringBuilder))
{
stringBuilder.Append(" ");
}
stringBuilder.Append("}");
return stringBuilder.ToString();
}
[System.Runtime.CompilerServices.NullableContext(1)]
protected virtual bool PrintMembers(StringBuilder builder)
{
builder.Append("FirstName");
builder.Append(" = ");
builder.Append((object)FirstName);
builder.Append(", ");
builder.Append("LastName");
builder.Append(" = ");
builder.Append((object)LastName);
return true;
}
[System.Runtime.CompilerServices.NullableContext(2)]
public static bool operator !=(Person left, Person right)
{
return !(left == right);
}
[System.Runtime.CompilerServices.NullableContext(2)]
public static bool operator ==(Person left, Person right)
{
return (object)left == right || ((object)left != null && left.Equals(right));
}
public override int GetHashCode()
{
return (EqualityComparer<Type>.Default.GetHashCode(EqualityContract) * -1521134295 + EqualityComparer<string>.Default.GetHashCode(<FirstName>k__BackingField)) * -1521134295 + EqualityComparer<string>.Default.GetHashCode(<LastName>k__BackingField);
}
[System.Runtime.CompilerServices.NullableContext(2)]
public override bool Equals(object obj)
{
return Equals(obj as Person);
}
[System.Runtime.CompilerServices.NullableContext(2)]
public virtual bool Equals(Person other)
{
return (object)this == other || ((object)other != null && EqualityContract == other.EqualityContract && EqualityComparer<string>.Default.Equals(<FirstName>k__BackingField, other.<FirstName>k__BackingField) && EqualityComparer<string>.Default.Equals(<LastName>k__BackingField, other.<LastName>k__BackingField));
}
[System.Runtime.CompilerServices.NullableContext(1)]
public virtual Person <Clone>$()
{
return new Person(this);
}
protected Person([System.Runtime.CompilerServices.Nullable(1)] Person original)
{
<FirstName>k__BackingField = original.<FirstName>k__BackingField;
<LastName>k__BackingField = original.<LastName>k__BackingField;
}
public void Deconstruct(out string FirstName, out string LastName)
{
FirstName = this.FirstName;
LastName = this.LastName;
}
}
Using sharplab lets define a class with the same properties. If we compare this to the code for what is effectively a really simple class.
public class Person
{
public string FirstName {get; set; }
public string LastName {get; set; }
}
The decompiled code for the Person class as defined below. You'll no doubt identify that the class is remarkably less complex.
using System.Diagnostics;
using System.Reflection;
using System.Runtime.CompilerServices;
using System.Security;
using System.Security.Permissions;
[assembly: CompilationRelaxations(8)]
[assembly: RuntimeCompatibility(WrapNonExceptionThrows = true)]
[assembly: Debuggable(DebuggableAttribute.DebuggingModes.Default | DebuggableAttribute.DebuggingModes.DisableOptimizations | DebuggableAttribute.DebuggingModes.IgnoreSymbolStoreSequencePoints | DebuggableAttribute.DebuggingModes.EnableEditAndContinue)]
[assembly: SecurityPermission(SecurityAction.RequestMinimum, SkipVerification = true)]
[assembly: AssemblyVersion("0.0.0.0")]
[module: UnverifiableCode]
public class Person
{
[CompilerGenerated]
[DebuggerBrowsable(DebuggerBrowsableState.Never)]
private string <FirstName>k__BackingField;
[CompilerGenerated]
[DebuggerBrowsable(DebuggerBrowsableState.Never)]
private string <LastName>k__BackingField;
public string FirstName
{
[CompilerGenerated]
get
{
return <FirstName>k__BackingField;
}
[CompilerGenerated]
set
{
<FirstName>k__BackingField = value;
}
}
public string LastName
{
[CompilerGenerated]
get
{
return <LastName>k__BackingField;
}
[CompilerGenerated]
set
{
<LastName>k__BackingField = value;
}
}
}
A record certainly has more code associated with it, so why?
To answer this question lets dig down in a simple example, of a very simple application using Records, in the code below.
We'll declare our person record object. Then we will create 3 Different Person records with all the same names then we will compare the objects to see if they have equal values, take note that we do not have an unique ID value on the record, and we want to be able to check if the 3 different objects we created are in some way equal to each other, to determine if they are the same person.
public record Person(string FirstName, string LastName);
class Program
{
static void Main(string[] args)
{
Person person = new("Gary", "Woodfine");
var person2 = new Person("Gary", "Woodfine");
var person3 = person with { FirstName = "Gary", LastName = "Woodfine" };
Console.WriteLine(person == person2);
Console.WriteLine(person2 == person3);
Console.WriteLine(person == person3);
}
}
If we execute the code, we'll see that all these objects are in fact equal to each other.
True True True Process finished with exit code 0.
Equality matters
A record type gets an implementation of the Equals method, to enable equality comparison of instances of record types. The implementation does value-based equality checks. meaning that if two instances of a record type have the same property values, they are treated as equal.
Lets try the same process with with a simple POCO class.
public class Person
{
public string FirstName { get; set; }
public string LastName { get; set; }
}
class Program
{
static void Main(string[] args)
{
var person = new Person { FirstName = "Gary", LastName = "Woodfine" };
var person2 = new Person { FirstName = "Gary", LastName = "Woodfine" };
var person3 = new Person { FirstName = "Gary", LastName = "Woodfine" };
Console.WriteLine(person == person2);
Console.WriteLine(person2 == person3);
Console.WriteLine(person == person3);
}
}
We execute the application and we'll see that despite the 3 classes having exactly the same values that they do not equal each other.
False False False Process finished with exit code 0.
So you see, this is actually the primary use case for records, immutable reference types that provide value semantics for equality. This can be extremely useful in Multi-threaded application scenarios, where you will often need to perform a comparison with objects to check if their values are equal or have changed, but the objects have no Unique Identifier. For instance, you may be passing an object to another process on a different thread and you want to ensure that when it returns the values have not been changed, hence you need the immutability and you have no Id or unique identifier to attach to the object.
Lets try something different we'll create a a Person Class object and Person Record object with exactly the same values then compare them.
public class PersonClass
{
public string FirstName { get; set; }
public string LastName { get; set; }
}
public record PersonRecord(string FirstName, string LastName);
class Program
{
static void Main(string[] args)
{
var personRecord = new PersonRecord("Gary", "Woodfine");
var personClass = new PersonClass { FirstName = "Gary", LastName = "Woodfine" };
Console.WriteLine(personClass.Equals(personRecord));
}
}
False Process finished with exit code 0.
It is possible to replicate some of the functionality that a Record provides by simply implementing the IEquatable interface on your class.
public class Person : IEquatable<Person>
{
public string FirstName { get; set; }
public string LastName { get; set; }
public bool Equals(Person other)
{
if (ReferenceEquals(null, other)) return false;
if (ReferenceEquals(this, other)) return true;
return FirstName == other.FirstName && LastName == other.LastName;
}
public override bool Equals(object obj)
{
if (ReferenceEquals(null, obj)) return false;
if (ReferenceEquals(this, obj)) return true;
if (obj.GetType() != this.GetType()) return false;
return Equals((Person)obj);
}
public override int GetHashCode()
{
return HashCode.Combine(FirstName, LastName);
}
}
class Program
{
static void Main(string[] args)
{
var person1 = new Person { FirstName = "Gary", LastName = "Woodfine" };
var person2 = new Person { FirstName = "Gary", LastName = "Woodfine" };
Console.WriteLine(person1.Equals(person2));
Console.WriteLine(person1 == person2);
}
}
If we execute this code, we'll see that only the Equals method works as expected. However, when we use the == operator it returns false, because we have not implemented the operator methods.
True False Process finished with exit code 0.
We can refactor Person class a little more and implement two Operator comparison as follows
public static bool operator == (Person left, Person right)
{
return (object)left == right || ((object)left != null && left.Equals(right));
}
public static bool operator !=(Person left, Person right)
{
return !(left == right);
}
If we then execute our application we'll see that our object comparison works effectively.
True True Process finished with exit code 0.
Value-based equality
All objects inherit a virtual Equals(object) method from the object class. This is used as the basis for the Object.Equals(object, object) static method when both parameters are non-null. Structs override this to have "value-based equality", comparing each field of the struct by calling Equals on them recursively. Records do the same. This means that in accordance with their "value-ness" two record objects can be equal to one another without being the same object.
C# records implement IEquatable<T> and overload the == and != operators, so that the value-based behaviour shows up consistently across all those different equality mechanisms.
We have been able to fairly easily replicate some of the functionality that a C# Record object provides for us, although C# Records also provide some additional implementation as regards the ability to easily clone objects and provide immutability. However, we can implement our class to be an immutable type by simply adding a constructor arguments and making our properties readonly as follows.
public class Person : IEquatable<Person>
{
public string FirstName { get; }
public string LastName { get; }
public Person(string firstName, string lastName)
{
FirstName = firstName;
LastName = lastName;
}
// rest of the implementation
}
If we now try to change the any of the property values in our code we'll get compiler errors as follows
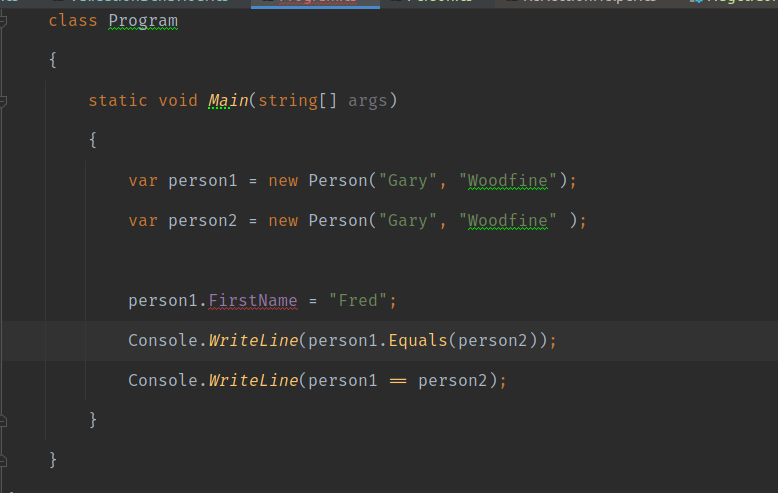
So without that much effort we have been able to replicate some of the functionality that C# Records provide, Although you'll also no doubt appreciate the ease of use the Syntax Sugar that provides.
Using Records in classes
You can use Records in a class to create immutable properties, for instance lets say we want to create a Full Name property for our Person class as follows:
public class Person
{
public FullName Name { get; init; }
}
public record FullName(string FirstName, string LastName);
This can be useful in situations when you are creating an object, which will have no unique Identifier and you want some form of unique identifier you can use to evaluate or identify the object later. We can name simply use our property as follows
If we execute our application we'll see that we get our name nicely rendered out
class Program
{
static void Main(string[] args)
{
var person1 = new Person { FullName = new FullName("Gary", "Woodfine") };
var person2 = new Person { FullName = new FullName("Gary", "Woodfine") };
Console.WriteLine(person1.FullName == person2.FullName);
}
}
The cool thing about using this approach is we now get an immutable property on our class and we can use the property in comparison operations.
True Process finished with exit code 0.
ToString()
Record types provide an implementation of the ToString method, enabling the transformation of property values of a record type into a string. The output contains the name of the record type and all properties, including their values. The format has a JSON-like syntax but starts with the name of the record type.
class Program
{
static void Main(string[] args)
{
var person = new Person { FullName = new FullName("Gary", "Woodfine") };
Console.WriteLine(person.FullName);
}
}
The key features of C# Record types
While records can be mutable, they're primarily intended for supporting immutable data models
Records (C# reference)
C# record types offer:
- read-only properties, which makes an instance of the type immutable without additional work such as defining fields or properties with specific keywords.
- a constructor with all properties as arguments without having to write the constructor itself.
- performance of value-based equality checks without overriding the GetHashCode and Equals methods.
- a textual representation of the object’s values and its type without overriding the ToString method.
- an implementation for the Deconstruct method, which allows us to use object deconstruction to access individual properties.
Use case for Record Types
Copying data
If we need to copy a data structure, record types provide us with a cloning mechanism that lets us do it on a single line.
Compare data
If we have business logic that needs to compare different objects’ properties, we can take advantage of the default value-based equality implementation that record types provide.
Parallelization
Immutability of record types are of the most use during the parallelisation of the computation of data. Primarily because If the data does not change, there is no need to synchronise access to it.
Putting Records in their place
So as we can see C# Records have their place in software development, and I can tell you that place is not everywhere! This is not to discourage the use of records, this is just to mindful of when and where to use them.
You can think of C# Records as a motor cycle crash helmet. They're great for providing some protection for your head in the event of a motorcycle accident and its great to wear them as a precaution when you're out on a motorbike. However, they're not that great to wear everywhere where you could potentially bump your head. For instance, you probably don't want to sleep in one, just in case you bump your head on your headboard during the night. You wouldn't want to wear one on a hot summers day down the beach, just in case someone throws a frisbee at your head.

Crash helmets have their use case and they I have to say some of them look really cool. However, personally I wouldn't buy one or use one primarily because I don't have a motorcycle. I wouldn't necessarily want to wear one while driving my car either.
So C# Records have their use cases and they are a great bit of syntactic sugar for when you want to create objects that implement IEquatable<T> Interface , which is used to define a generalised method that a value type or class implements to create a type-specific method for determining equality of instances.
One of my biggest concerns regarding C# Records, usually starts when I hear or see developers use statements as the following:
Working with immutable data is quite powerful, leads often to fewer bugs, and it forces you to transform objects into new objects instead of modifying existing objects. F# developers are used to this, as F# treats everything by default as immutable.
There is quite a bit wrong with this statement. First and foremost, I'll deal with the fact that immutable objects don't necessarily lead to fewer bugs. They certainly do help to reduce bugs in Multi-threaded parallelised applications, when you want to ensure the values of properties on your class are not changed during processing on the same physical machine on different threads. But they not great when you're using them in using them in a distributed microservice architecture when the processing is spread across multiple different machines, let alone processes.
Secondly, ensuring you transform objects into new objects instead of modifying existing objects, doesn't necessarily mean things are safer. Although C# Records do come with a virtual Clone method by default, that returns a new record initialised by the copy constructor, which help to reduce bugs. Unfortunately, the instances I've seen records being used, is that developers create a new object then copy the individual properties over. Similarly to when using Automapper, basically transforming an immutable object into another immutable object in order to pass it to another layer in the application.
The problem enforcing the creation of new objects, is that you're potentially enforcing developers to create a new object and potentially they will create new objects and forget to copy some vital properties over, hence deliberately enforcing bugs.
public virtual FullName <Clone>$()
{
return new FullName(this);
}
Lets create a Trivial bug using our immutable C# Record objects, what do you think will be printed out here?
I'm going to make use of the with expression in derived records
public class Person
{
public FullName FullName { get; set; }
}
public record FullName(string FirstName, string LastName);
class Program
{
static void Main(string[] args)
{
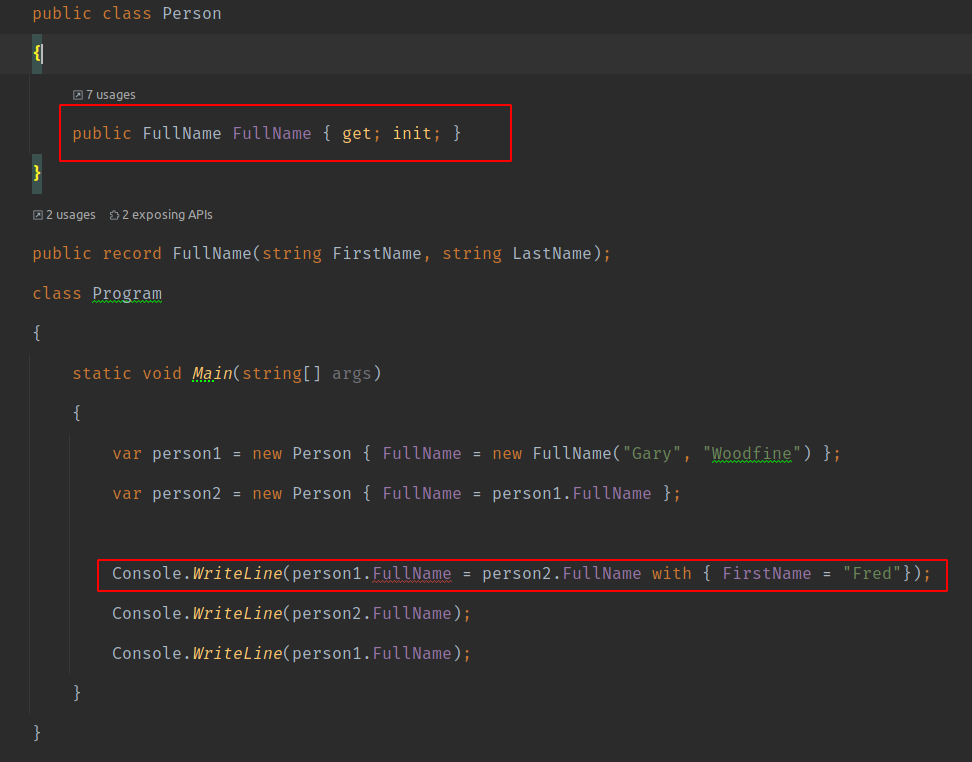
var person1 = new Person { FullName = new FullName("Gary", "Woodfine") };
var person2 = new Person { FullName = person1.FullName };
Console.WriteLine(person1.FullName = person2.FullName with { FirstName = "Fred"});
Console.WriteLine(person2.FullName);
Console.WriteLine(person1.FullName);
}
}
The bug here may be a little obvious to spot, but you'll be surprised how often I have come across this specific scenario in code bases, which has not always been so obvious to spot. So wait how come we've managed to change the value of our Immutable type?
Well there are a couple of answers here. Firstly, one of the causes comes in the declaration of our class
public class Person
{
public FullName FullName { get; set; }
}
We've inadvertently enabled the setting of a new value for our record type, by providing a setter. We can fix this by making use of some additional syntax sugar provided in C# 9.0, init only setters. If we change the declaration our class as follows:
public class Person
{
public FullName FullName { get; init; }
}
We will now get a nice compile error telling us that the operation we wanted to perform cannot be done because the setting values of Record property can only be done during the initialisation of our class.
The second bug is primarily because I've broken Clean Code principles and I actually have very badly named and confusing variables but they serve for the purpose of this article.
What I wanted to do here, is create a new new person2 class but use the some of the same values of Person2 Fullname but only change the Firstname to create a completely new person object. This can be achieved as follows now that I have limited the changing of FullName property to initialisation of the class.
public class Person
{
public FullName FullName { get; init; }
}
public record FullName(string FirstName, string LastName);
class Program
{
static void Main(string[] args)
{
var person1 = new Person { FullName = new FullName("Gary", "Woodfine") };
var person2 = new Person { FullName = person1.FullName with { FirstName = "Fred"} };
Console.WriteLine(person1.FullName);
Console.WriteLine(person2.FullName);
}
}
So as we can see, C# Records just by themselves won't necessary help to eliminate or reduce bugs, just because of their immutable nature and to be frank that really has nothing to do with them. Thirdly my biggest gripe, is primarily to do with this nonsense of always trying to compare C# with F#, because the reality it is they are really too completely different things.
C# is an Object-Oriented Programming language and F# is a Functional Programming Language and the two are very different things both from a conceptual level and really to what problems they attempt to solve.
C# is a language that is termed naturally mutable type language, what this means that a vast majority of objects types are mutable by default . A number of Object-oriented programming languages, Java, Python, C++ etc, fall into this camp. In fact, in C# only a handful of types are immutable by default such as String and DateTime once you set a value on those objects they cannot be changed, without creating a new instance of the object and copying or transforming the contents of the data to the new object.
The primary use case, for these types of Object-Oriented languages is essentially for the manipulation of data and performing some calculations and returning results.
A functional language or technique is one in which the sole or dominant form of expressing algorithms is the evaluation of mathematical functions, avoiding state changes and mutable data. This is as against declarative, imperative, and procedural languages/techniques, which emphasise changes in state.
Functional languages are great when solving problems that require lots of concurrency and parallelism. Your average Line of Business web application or REST API micro service, probably 80-90% won't need this, not to say that your application may call out to a Module/Class/Service/Application/Dll developed in a functional language to execute some complex algorithm, but that doesn't mean you have to develop your entire application stack in a F# or use Functional Programming language paradigms. This is again is about ensuring make use the right tool for the right job.
When developing developing your typical business application whether it be a Microservice, Rest API, Website or whatever, you can probably count on your one hand the amount of times you'll run into a situation where the mutable state of your object will cause you any real problems, in fact this mutable feature of your objects works pretty much in your favour.
I have worked on advanced software applications where immutable objects, concurrency and Parallelisation are a primary concern, These were applications like Flight Simulators, financial trading, games and cyber security threat analysis. Even in those applications, it made sense use the best tools for the job. Often across the entire stack you'll see a mixture of C++, F#, Haskell, Rust etc. To essentially use the advanced features and concepts of these languages to get the best performance.
It clearly didn't make sense to use Scala to develop the entire stack. So the lesson here, just because a feature exists in programming language it definitely doesn't mean you should use it. It's about understanding the use case for it.
Immutability is not all that its cracked up to be
The number one thing most developers will respond with when you ask them why they have used C# records, they comeback with immutability . which is great and all, but it completely falls apart if the code they using in their immutable objects is no way highly multi-threaded!
I get the immutability argument, but like all things in life in general it has its time and place. if implemented poorly it can also severely impact performance of your application due to the overhead generated by creating new objects.
Using immutable types does offer some benefits, but it is by no means the silver bullet to cure all problems. They can also cause some unintended consequences too.
Not everything in C# can be made immutable. There are thousands of classes in the framework. Not everything needs to be immutable. Not every use case calls for immutability. Second, there will be the need for some custom code. Full immutability doesn't come straight out of the box. Therefore, you'll have to implement some code. The good news is that it's not a lot of code to worry about!
It's a misconception to think that C# Records provide immutability, the fact is they also provide functionality for very different use cases too. If immutability is a genuine concern there are different patterns practices you can easily implement in C#.
Further more, parameter passing in C# can either be by value or by reference. (Passing Parameters (C# Programming Guide))
In C#, arguments can be passed to parameters either by value or by reference. Passing by reference enables function members, methods, properties, indexers, operators, and constructors to change the value of the parameters and have that change persist in the calling environment. To pass a parameter by reference with the intent of changing the value, use the
ref, oroutkeyword.
When Immutability matters
There are use cases in software development when in immutability matters and there are cases when immutability doesn't matter. The use case where immutability matters is when you are going to pass your object to another process or thread and you want to ensure those processes don't change the value of your object because once those processes return your object your process will continue processing the values on your object.
The key phrase here, is that your processes are dependent on the return value. There is no point, trying to control the mutability of your object when you pass it to processes beyond your control, if you are not going to rely on the state of the values.
I see this time and again, where a immutable object is passed to a process and the first thing the process does is copy the values from the immutable object to a new mutable object and the mutable object is then used in the continuing process, worst of the the immutable object is never actually returned to the caller method!
Immutability can be useful when you need a data-centric type to be thread-safe or you're depending on a hash code remaining the same in a hash table. Immutability isn't appropriate for all data scenarios, however. Entity Framework Core, for example, doesn't support updating with immutable entity types.
Records (C# reference)
Don't use C# Records in API Controllers
One of the areas, I see often see the misuse of C# Records is in API Controllers. It really doesn't make any sense for a couple of reasons. The first one should be immediately obvious from the start REST by it's very nature is meant to be stateless. REST-compliant systems, often called RESTful systems, are characterised by how they are stateless and separate the concerns of client and server.
In the REST architectural style, the implementation of the client and the implementation of the server can be done independently without each knowing about the other. This means that the code on the client side can be changed at any time without affecting the operation of the server, and the code on the server side can be changed without affecting the operation of the client.
So I have to ask the reason, why would you want to try and manage the state of an object over a protocol that is by its nature meant to be stateless ?
Your API will have and should never have any state information about the object that is coming in, from your API perspective it is always going to be a new object and it is going to have to do something with it regardless in all likelihood it is going to change the state of the object. When developing microservices you should always be wary of passing around data in requests when you don't know its freshness.
In many cases the primary objective of a REST API is the provide the capability to mutate the state of an object.
This is best served with an example of just how unnecessary this is, when reviewing a snippets of sample production code I found in a system of several API endpoints.
[HttpGet("{id}")]
[ProducesResponseType((int)HttpStatusCode.NotFound)]
[ProducesResponseType((int)HttpStatusCode.OK, Type = typeof(LocationBaseDto))]
public async Task<IActionResult> Get(GetLocationByIdRequest request, CancellationToken cancellationToken)
{
var query = request.ToQuery();
var location = await _mediator.Send(query, cancellationToken);
var locationDto = location.ToDto();
return Ok(locationDto);
}
/// The GetLocationByIdRequest
public record GetLocationByIdRequest : RequestBase
{
[FromRoute(Name = "id")] public string Id { get; init; }
}
/// Request Base
public record RequestBase
{
[FromHeader(Name = "X-Origin")]
[Required]
public string Origin { get; init; }
[FromHeader(Name = "X-Username")]
[Required]
public string Username { get; init; }
}
Fundamentally this is pointless code. To sum up here, a Record object has been passed in from outside, if remember the primary benefit of the C# Records is that they implement the IEquality interface, at no point in the code do we actually test if the object we have received is actually Equal to anything?
Then the very next step we actually just convert it to another record object via an extension method, in the process we actually lose some vital and useful information relating to the original request i.e. The Origin and the Username. Why have we asked for and more or less insisted that information be on the request by creating a base object?
Then for some obscure reason, some kind of validation logic is executed in the constructor and throws an exception, which you'll see is not actually caught or managed by the controller!
The question I have to ask in this scenario, is why have we insisted that an IEquality object is sent over the wire if we are not actually going to check if it is equal to anything? This is absolutely just pointless. It's using C# Records for absolutely no benefit, other than they're a cool new language feature!
public static class LocationQueryResolver
{
public static GetLocationByIdQuery ToQuery(this GetLocationByIdRequest request)
{
return request == null ? throw new BadInputParametersException("Check input parameters") : new GetLocationByIdQuery(request.Id);
}
}
// LocationBase Record
public record GetLocationByIdQuery : IRequest<LocationBase>
{
public GetLocationByIdQuery(string locationId)
{
Id = !string.IsNullOrWhiteSpace(locationId)
? locationId
: throw new ArgumentNullException(nameof(locationId));
}
public string Id { get; }
}
The code above creates yet another new Record type with essentially vital data missing, we didn't even make a copy or clone the object to send we created a whole new object. So again, why have we essentially asked our calling application to send us an immutable object if the first thing we're going to do with it is create a completely different object to use in our processing!
Taking a look at the assumed immutable object, i.e. RequestBase we'll notice that it is not actually immutable, because in effect it has not been declared using positional syntax, therefore in that case the record is actually declared as a mutable object.
Things go from bad to worse in the code sample, not only do we change the object before we send it off to our Mediator process, but the Records go through several transformations in stages withing the Mediator Pipeline and the when the Mediator pipeline returns the response is a C# Record type, which we then convert to an entirely different object to send back to the client!
All this for absolutely no benefit, introducing completely unnecessary cyclomatic complexity, as you may well know from chapter 2 of A philosphy of software design is something we as software developers need to strive to minimise in our systems.

A Philosophy of Software Design
addresses the topic of software design: how to decompose complex software systems into modules (such as classes and methods) that can be implemented relatively independently.
Everytime I see C# Records being used in API controllers I see the same patterns. I just have to ask myself why!
Mutability concerns
If you're concerned about the mutability of objects in your application, this may actually be a symptom of deeper architectural problems in your application. You may discover what you're actually experiencing may typically be what is known as the Architecture Sinkhole anti pattern. Every layered architecture will have at least some scenarios that fall into the architecture sinkhole anti-pattern
In this anti-pattern Requests flow through multiple layers of the architecture as simple pass-through processing with little or no logic performed within each layer. The further the object flows through multiple layers the more concerned developers will grow about values being changed on objects as they pass through.
This anti pattern is discussed in Fundamentals of software architecture and typically this anti pattern may arise due to the implementation of the Layered Architecture.
The layered architecture pattern, is one of the most common architecture style, and many would view it is the defacto standard for most applications primarily due to its simplicity, familiarity and low cost to implement.
Components within the layered architecture style are organised into logical horizontal layers each layer performing a specific role within the application. Although there are no specific rules or restrictions on the number of layers that must exist most layered architectures would consist of layers such as Presentation, Service, Business Rules, Domain, Repository, Data access etc.
The layered architecture is technically partitioned as opposed to domain partitioned. As a result any particular business domain is spread throughout all of the layers of the architecture.
A request moves top-down from layer to layer and a request cannot skip any layers and must go through the layer immediately below it to get to the next layer.

Fundamentals of Software Architecture
An Engineering Approach
provides the first comprehensive overview of software architecture's many aspects. Aspiring and existing architects alike will examine architectural characteristics, architectural patterns, component determination, diagramming and presenting architecture, evolutionary architecture, and many other topics.
Using C# Records as Value Objects
Domain-Driven Design: Tackling Complexity in the Heart of Software discusses Value Objects.
An object that represents a descriptive aspect of the domain with no conceptual identity is called a Value Object. Value Objects are instantiated to represent elements of the design that we care about only for what they are, not who or which they are.
Eric Evans
Simply put, value objects don’t have their own identity. For the most part we don’t care if a value object is the same physical object we had before or another one with the same set of properties. Value Objects are completely interchangeable.
Attributes of Value Objects
- No identity. value objects are identity-less nature is, obviously, not having an Id property. Unlike entities, value objects should be compared by value, not by identity field.
- Immutability. As any value object can be replaced by another value object with the same property set, it’s a good idea to make them immutable to simplify working with them, especially in multithread scenarios. Instead of changing an existing value object, just create a new one.
- Lifetime shortening. Value Objects can’t exist without a parent entity owning them. In other words, there always must be a composition relationship between a Value Object class and an Entity class. Without it, value objects don’t make any sense.
- Value Objects should not have separate tables in database. This one is an attribute programmers find the most controversial.
Value Objects are the backbone of any rich domain model. C# records could at first be a potentially good fit for DDD Value Objects  because they provide the same semantics and do all the hard lifting behind the scenes. However, there are couple of caveats.
IComparable Interface
Unfortunately, C# records don’t implement the IComparable interface , which isn't a complete deal breaker because for the most part the IEquality interface can suffice.
Vladimir Khorikov discusses this far more eloquently and in more detail than I could in C# 9 Records as DDD Value Objects. I recommend reading his post, because it does provide some excellent detail and thought provoking viewpoints and insights to using C# Records in general. He also provide clarity on the potential use cases for C# Records.

Domain Driven Design
Tackling Complexity in the Heart of Software
A fantastic book on how you can make the design of your software match your mental model of the problem domain you are addressing
Conclusion
C# Records are a nice language feature, albeit more or less a little syntactic sugar to create a class that implements the IEquality Interface. Please refrain from using C# Records in your Web or API controllers, there is absolutely no need for them there in probably 98% of the use cases.
C# Records make sense as interim data classes while loading or retrieving data from a database or doing some pre or post processing of the data before it is committed or dispatched to your Domain Layer.
Just because a language has a feature, it doesn't necessarily means you have to use it. It's nice to know its there for when the opportunity arises for you to use it, but you don't have to use it just because its there. I am specifically encountering cases where C# records have become the equivalent of the Golden Hammer anti pattern

- What is this Directory.Packages.props file all about? - January 25, 2024
- How to add Tailwind CSS to Blazor website - November 20, 2023
- How to deploy a Blazor site to Netlify - November 17, 2023