

Managed and unmanaged code are two types of code that differ in how they handle memory management. In this article, we’ll explore the differences between managed and unmanaged code, focusing on garbage collection.
Let’s begin.
What Is Managed Code?
Managed code is code that executes in a runtime environment that provides automatic memory management, also known as garbage collection.

Garbage collection is a process in which the runtime environment automatically manages the memory used by an application by freeing unused memory and reclaiming it for future use. This makes it easier for us to write code because we do not have to worry about allocating and freeing memory.
Let’s create a class to understand this better:
public class ManagedMemoryManager
{
private readonly List<int> _numbers;
public ManagedMemoryManager()
{
_numbers = new List<int>();
}
}
Here we have a class that initializes a List<int> object in the constructor. It is responsible for allocating memory by adding a million integers to the initialized object.
Let’s create a method to add some values to our list:
public void AllocateMemory()
{
for (var i = 0; i < 1000000; i++)
{
_numbers.Add(i);
}
}
Here, the .NET runtime handles garbage collection automatically.
We can use the GC.GetTotalMemory() method to get the memory allocated to the List<int>:
var memoryManager = new ManagedMemoryManager();
var memoryBeforeAllocation = GC.GetTotalMemory(false);
memoryManager.AllocateMemory();
var memoryAfterAllocation = GC.GetTotalMemory(false);
Console.WriteLine($"Memory Allocated to the list: {memoryAfterAllocation - memoryBeforeAllocation} bytes");
By subtracting the value memoryBeforeAllocation from the value memoryAfterAllocation, we can determine the amount of memory allocated by the AllocateMemory() method.
When an instance of the ManagedMemoryManager class is no longer in use, the garbage collector detects this and releases the memory that was allocated for the _numbers list.
Memory Management in Managed Code
In managed code, the runtime environment is responsible for allocating and deallocating memory.
When we create a new object, the runtime environment allocates the required memory for the object on the heap. When the object is no longer needed, the runtime environment releases the memory allocated for the object.
The garbage collector periodically checks for objects that the application no longer needs. When it finds such objects, it releases the memory allocated for those objects.
An important aspect of managed code is dependency injection. We use this technique to manage the dependencies of a software system.
We can use dependency injection to specify the lifetime of an object in memory. This is important because keeping objects in memory for too long can cause performance issues as objects consume valuable memory resources.
These lifetimes include Transient, Scoped, and Singleton. Transient creates a new instance of an object each time it is requested, which is useful for short-lived or unshared objects. Scoped creates an object once per request or unit of work, which is useful for objects we are using in multiple components within a request. Singleton creates an object once and reuses it throughout the life of the application. This is useful for expensive objects or those that need to maintain their state across multiple requests.
By using an appropriate lifetime for each object, we can ensure that our code is efficient and performs well while reducing the risk of memory leaks and other issues.
Memory Analytics in Managed Code
Memory analysis is essential to identify and fix memory-related problems in our applications. Let’s take a look at how we can use the Visual Studio Performance Profiler to accomplish this.
For memory analysis, we can go to the Debug menu and select Performance Profiler. Once the Performance Profiler window opens, we can choose the Memory Usage option.
Clicking the Start button in the Performance Profiler window will start the profiling session. Once the profiler session is active, we can click on the Take Snapshot option to capture a memory snapshot in the current state of the application.
We can take multiple snapshots to analyze these snapshots individually or compare them to identify any changes or issues in memory usage between those points in time:
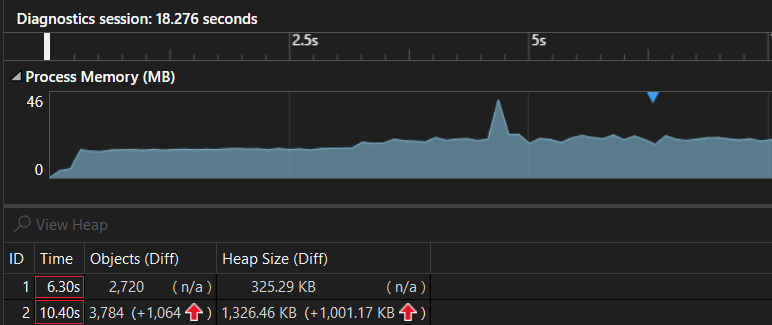
Here, we have two snapshots at 6.30 s and 10.40 s of the program execution respectively.
The first snapshot indicates that compared to the initial state, there was an increase of 2,720 objects in memory. Additionally, the heap size grew by 325.29 KB. While, at a later point in time there was a further increase of 3,784 objects in memory compared to the initial state. The heap size also grew significantly by 1,326.46 KB.
Advantages and Disadvantages of Managed Code
Because the runtime environment takes care of memory management, memory-related errors are less likely to occur. Also, it is able to perform additional security checks to prevent buffer overflows and other related security vulnerabilities.
Another advantage of managed code is portability. The runtime abstracts away the details of the underlying hardware and operating system and provides a consistent interface for accessing system resources. This allows applications written in managed code to run on any platform that supports the runtime environment without requiring modification or recompilation.
Although managed code offers several advantages, there are also some potential disadvantages to consider.
The most significant disadvantage is that we have limited control over memory. While this can be an advantage in terms of simplicity and security, it can also be a disadvantage for applications that require fine-grained control over memory.
In addition, garbage collection in managed code can have a performance overhead. It periodically scans the heap to identify objects that are no longer in use, and this can cause a temporary interruption in application execution.
What Is Unmanaged Code?
In C#, unmanaged code refers to code that operates outside the memory management and safety features provided by the .NET runtime. For unmanaged code, we are responsible for manually managing the memory, which means we must explicitly allocate and free the memory.
Typically, we write unmanaged code in languages such as C and C++ and compile it directly into machine code specific to the platform and architecture on which we compiled it.
However, we can also write unmanaged code in C#. It involves interacting with native code in the unsafe context or interoperability with external libraries using platform-specific APIs.
Unmanaged code can be highly optimized for the hardware on which it runs, which can lead to better performance in some cases.
Unsafe Context
The unsafe keyword in C# allows us to bypass some of the safety features provided by the .NET runtime and work with pointers directly. We often use it when performing low-level operations or working with unmanaged memory:
var numbers = new int[] { 1, 2, 3, 4, 5 };
unsafe
{
fixed (int* ptr = numbers)
{
for (var i = 0; i < 5; i++)
{
Console.WriteLine(*(ptr + i));
}
}
}
Here, we make use of the unsafe context to work with pointers to access elements of an array. The fixed statement pins the numbers array in memory, ensuring it won’t be moved by the garbage collector.
However, using unsafe code can lead to issues such as buffer overflows, memory leaks, and security vulnerabilities. Therefore, we should use it with caution and only when absolutely necessary.
Interoperability With Unmanaged Code Libraries
C# provides a mechanism to interoperate with unmanaged code through the DllImport attribute. This attribute allows us to import functions from native libraries into our managed code, enabling direct access to the unmanaged functionality.
Let’s see this by calling the MessageBox function from the user32.dll library to display a message box:
[DllImport("user32.dll", CharSet = CharSet.Unicode)]
public static extern int MessageBox(IntPtr hWnd, string text, string caption, int options);
This function is not managed by the .NET runtime and requires invoking unmanaged code. We can use the MessageBox() function within our C# code to display a message box:
static void Main(string[] args)
{
MessageBox(IntPtr.Zero, "Hello, World!", "Message", 0);
}
By combining these aspects of unmanaged code, we can leverage external libraries and low-level memory operations while maintaining the robustness and benefits of the .NET CLR(Common Language Runtime).
Memory Management in Unmanaged Code
Unmanaged code involves direct memory manipulation using pointers and does not benefit from the automatic memory management features provided by the runtime. This means that we must manually allocate and deallocate memory as needed during the execution of the program.
In unmanaged code, we can allocate and deallocate memory manually using functions like Marshal.AllocHGlobal() and Marshal.FreeHGlobal().
These functions allocate memory on the unmanaged heap, allowing us to control the lifetime of the memory explicitly:
public class UnmanagedMemoryManager
{
public static IntPtr AllocateUnmanagedMemory(int size)
{
IntPtr ptr = Marshal.AllocHGlobal(size);
return ptr;
}
public static void FreeUnmanagedMemory(IntPtr ptr)
{
Marshal.FreeHGlobal(ptr);
}
}
In addition, when dealing with unmanaged code, it’s often beneficial to interoperate with managed code whenever possible.
This approach allows us to leverage the automatic memory management provided by the Common Language Runtime (CLR) and simplifies memory management in the application.
We can use Platform Invoke (P/Invoke) to achieve this. It allows us to call functions defined in unmanaged libraries from managed code.
By declaring the function signatures using the DllImport attribute and providing the necessary marshaling information, we can seamlessly invoke unmanaged functions while letting the CLR handle memory management for the managed parameters and return values.
Unmanaged Code Advantages and Disadvantages
Unmanaged code offers some advantages over managed code. It can provide finer control over system resources, which may be important for certain performance-critical or resource-constrained applications.
However, because of manual memory management, unmanaged code also has disadvantages. Failure to deallocate memory can result in memory leaks or memory corruption, which can lead to crashes, or security vulnerabilities. Also, it can lead to memory access violations if we try to access memory that is already deallocated.
In addition, the compiler usually compiles unmanaged code into native machine code that is specific to the underlying hardware and operating system. This can make it difficult to port unmanaged code to other platforms or architectures.
Finally, interoperating between managed and unmanaged code can introduce complexity and potential compatibility issues. Marshaling data between managed and unmanaged memory requires careful handling and can be error-prone.
Managed vs Unmanaged Code
The decision of whether to use managed or unmanaged code depends on the specific requirements and constraints of the project.
However, we can consider some of the most important factors and make an informed decision.
Performance of Managed vs Unmanaged Code
Unmanaged code can provide better performance because it has direct access to hardware resources and avoids the overhead of the runtime environment.
However, modern runtime environments such as .NET have achieved significant performance improvements and can often achieve similar performance to unmanaged code.
Security
Managed code can offer better security since the runtime environment can enforce memory safety and prevent certain types of vulnerabilities such as buffer overflows.
Unmanaged code can be more susceptible to security vulnerabilities if not written carefully.
Interoperability
Unmanaged code provides more control and access to system-level resources, which may be necessary for interoperability with certain hardware or legacy systems.
However, we can design managed code to interoperate with unmanaged code by using platform invocation services (P/Invoke) and COM interop.
Existing Code Base
In real-world scenarios, this is one of the most important factors to consider.
If there is already a large code base in a language or environment, it may be easier to continue using that language or environment than to switch to a new one.
Best Practices for Memory Management of Managed and Unmanaged Code
To avoid memory-related issues in managed and unmanaged code, it’s important to follow memory management best practices.
Let’s look at some of the best practices to follow in the case of both managed and unmanaged code.
Best Practices for Managed Code
We should avoid creating unnecessary objects or allocating memory unnecessarily.
This becomes clear when working with string objects:
var str = string.Empty;
for (var i = 0; i < 1000000; i++)
{
str += i.ToString();
}
Here, a new string object is created each time the loop runs, leading to unnecessary memory allocation. This can be particularly inefficient when working with large strings or when the loop runs many times.
Instead, we can use a StringBuilder object to efficiently build a string by appending to it in the loop:
var sb = new StringBuilder();
for (var i = 0; i < 1000000; i++)
{
sb.Append(i);
}
var result = sb.ToString();
This avoids the unnecessary creation of objects and improves memory management.
The GC.GetTotalMemory() method shows that using StringBuilder consumes significantly less memory than string concatenation:
Memory used by string concatenation: 4119208 bytes Memory used by StringBuilder: 161984 bytes
We should explicitly dispose of unmanaged resources to avoid memory leaks.
We can achieve this by implementing the IDisposable interface and calling the Dispose() method:
public static void WriteDataToFile(string fileName, string data)
{
var fileStream = new FileStream(fileName, FileMode.Create);
try
{
var bytes = Encoding.UTF8.GetBytes(data);
fileStream.Write(bytes, 0, bytes.Length);
}
finally
{
fileStream?.Dispose();
}
}
Here, we have a FileStream object which we use to write data to a file.
FileStream is an unmanaged resource because it represents a connection to a file system resource that is outside the .NET-managed memory space. It uses the file-processing services of the operating system, which the runtime environment of . NET doesn’t automatically manage.
Therefore, we need to explicitly dispose of it to avoid memory leaks. We wrap the usage of the FileStream object in a try block and dispose of it in a finally block.
Also, we could use the using statement and rewrite the method:
public static void WriteDataToFile(string fileName, string data)
{
using var fileStream = new FileStream(fileName, FileMode.Create);
var bytes = Encoding.UTF8.GetBytes(data);
fileStream.Write(bytes, 0, bytes.Length);
}
The using statement provides us a shorthand for calling the Dispose() method on an object that implements the IDisposable interface.
It automatically disposes of the object when the statement terminates. This simplifies the code and ensures that the FileStream is always disposed of properly, even if an exception occurs.
Best Practices for Unmanaged Code
We should always properly handle memory allocation and deallocation.
We can use the Marshal.AllocHGlobal() method to allocate memory and the Marshal.FreeHGlobal() method to deallocate memory. This prevents memory leaks.
We should always use proper techniques for data marshaling.
It can ensure data consistency, prevent memory issues, handle data size differences, and manage memory ownership effectively. This promotes correct and efficient communication between managed and unmanaged code, reducing errors and improving the overall performance and reliability of the application.
Depending on the data type, size, and memory layout, we should select the appropriate marshaling attributes or techniques:
var input = "Purple Jackets";
IntPtr unmanagedString = Marshal.StringToHGlobalAnsi(input);
Marshal.FreeHGlobal(unmanagedString);
The StringToHGlobalAnsi() method converts the managed string to an unmanaged null-terminated ANSI string and allocates the necessary memory in unmanaged memory space. It returns an IntPtr pointing to the allocated memory block that contains the converted string.
When working with unmanaged code in C#, it’s important to pay attention to memory layout and alignment.
Unmanaged code often relies on specific memory layouts for data structures. The memory layout determines the order and arrangement of individual members within a structure. Ensuring that the memory layout matches between managed and unmanaged code is crucial for the correct interpretation and manipulation of data.
Also, with interoperability, it’s important to align data structures to match the expectations of unmanaged code. Misalignment can lead to data corruption, incorrect interpretation, or crashes.
To control memory layout and alignment in C#, we can use attributes from the System.Runtime.InteropServices namespace.
One of the most commonly used attributes is StructLayout. It allows us to specify the layout of a structure in memory:
[StructLayout(LayoutKind.Sequential, Pack = 1)]
struct ToyCarInfo
{
public byte Color;
public int ModelNumber;
public float Weight;
}
Here, LayoutKind.Sequential ensures that the fields of the structure are laid out sequentially in memory, without any padding between them. Pack = 1 specifies that the structure should be packed tightly, ensuring that there is no padding added by the compiler or runtime.
Tools for Memory Management of Managed and Unmanaged Code
In addition to memory management best practices, there are also various tools and techniques that can help us manage memory more efficiently.
Let’s take a look at some of the memory management tools in Visual Studio.
Visual Studio Memory Profiler
This tool helps us analyze the memory usage of our code by profiling our application’s memory allocation and tracking memory leaks.
We can use it to see how much memory our program allocates, where it allocates the memory, and where it frees it. The tool also includes a heap summary view that shows us a breakdown of heap usage.
Code Analysis Tools
Visual Studio includes several code analysis tools, including Code Analysis and FxCop. These tools can help us identify memory-related issues, such as potential memory leaks and improper pointer usage.
Static Analysis Tools
Visual Studio also includes static analysis tools, such as Prefast and Cppcheck.
We can use these tools to detect memory-related problems at compile time, even before running our code. For example, they can warn us when we use uninitialized variables or when we dereference null pointers.
Memory Dump Analysis
If we encounter a memory-related problem at runtime, we can use Visual Studio’s memory dump analysis feature to examine the contents of application memory.
This can help us identify issues such as memory leaks, heap corruption, and other memory-related problems.
Conclusion
In this article, we have learned about managed and unmanaged code. We learned that both have their strengths and weaknesses when it comes to memory management.
The decision between managed and unmanaged code depends on the specific requirements and constraints of a project. As a programmer, it’s important to be familiar with both types of memory management and apply the best practices for each to ensure efficient and safe use of resources.
So many things got so much clearer :)! I liked the article a lot.
Hi Vaiva. Glad to hear that. Thanks for the comment.